
Welcome to our May Data & AI report! This month, we explore developments in data, AI, and machine learning. From transforming data warehouses to pioneering AI/ML applications.
Discover how industry leaders are pushing the boundaries of what’s possible⤵️
Are data warehouses evolving beyond analytics?
Mikkel Dengsøe, founder of Synq released some interesting research about the evolving role of data warehouses this month. Once the domain of reporting and analytics, we’re increasingly seeing them underpin crucial functions like AI/ML, automated marketing, and regulatory reporting. This evolution ups the stakes significantly and means that data accuracy is a top concern for most companies.
Mikkel also points out how data teams and their stacks are growing rapidly. Companies today manage thousands of models and juggle numerous daily jobs to keep things running smoothly. With more business-critical data and a surge in data assets, effective testing approaches are more vital than ever. It seems that basic tests won’t cut it anymore and that niche solutions will be essential to maintain data reliability.

Data warehouses now have to support business-critical uses like AI/ML, automated marketing, and regulatory reporting.
You can check out Mikkel’s full blog here.
What’s next for Uber’s ML platform, Michelangelo?
In a recent blog from Uber, the company shares the strides it’s made so far in machine learning (ML). Since 2016, Michelangelo, Uber’s centralised ML platform, is leveraging data to drive key functions like ETA predictions, rider-driver matching, rankings, and fraud detection. With around 400 active ML projects and over 5K models in production, Michelangelo manages 20K model training jobs monthly and delivers up to 10 million real-time predictions per second.
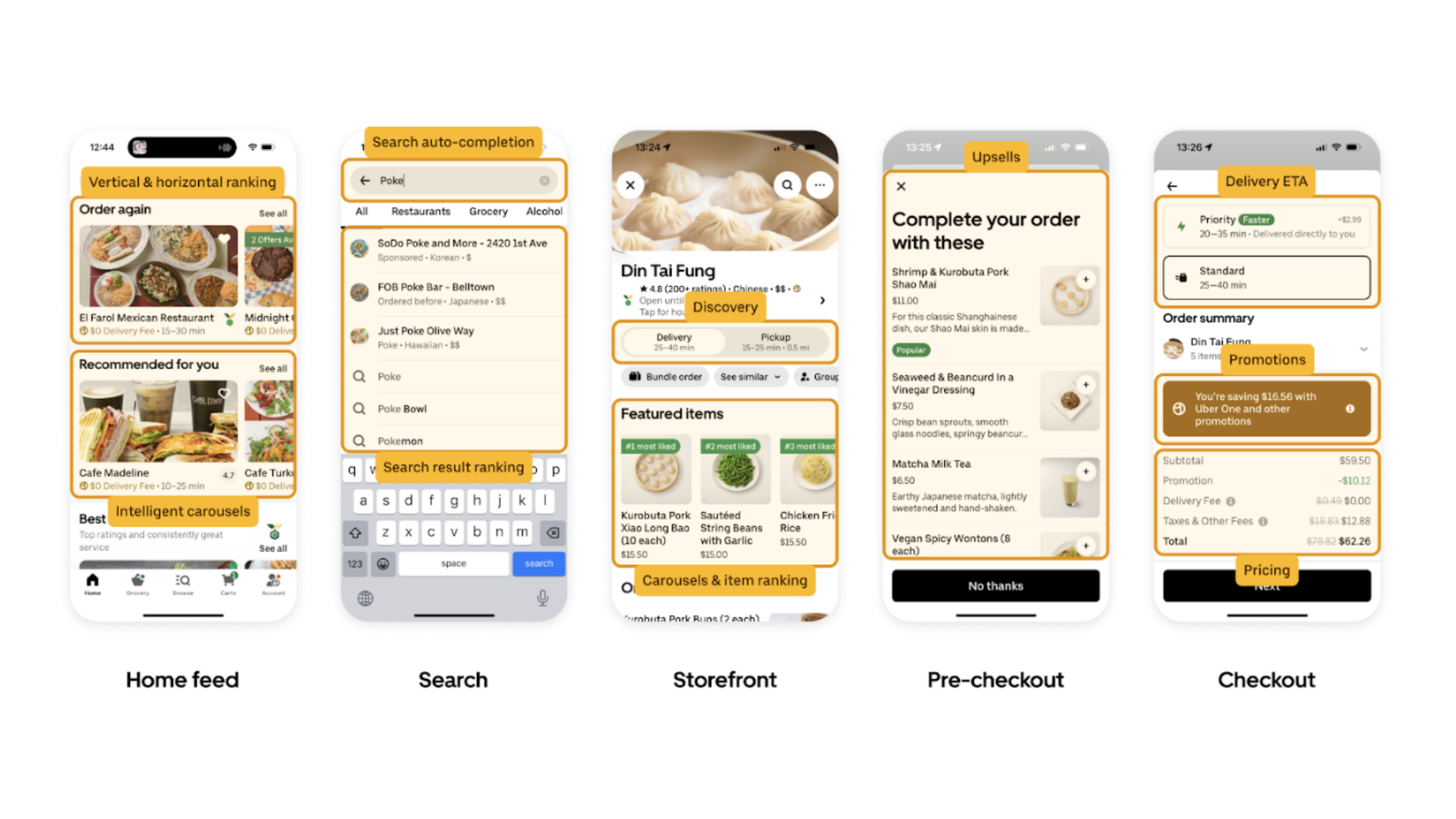
Real-time ML underpins Eater app core user flow.
The blog goes on to explain Uber’s plans to use generative AI and large language models (LLMs), with the Gen AI Gateway is at the forefront of its mission. With the aim to aid security, efficiency, and cost-effectiveness.
Read the full blog here.
LinkedIn launches LakeChime
This month, LinkedIn introduced LakeChime, a powerful data trigger service designed to enhance the efficiency of their extensive data lake. Handling billions of data points daily, LakeChime streamlines data processing by unifying data trigger semantics across both modern and traditional table formats like Hive and Iceberg.
Central to LakeChime is the Data Change Event (DCE), which captures updates within data tables and triggers downstream workflows via platforms like dbt or Airflow. This innovation ensures timely data availability and enhances pipeline efficiency.
Looking forward, LinkedIn plans to integrate LakeChime with dbt and Coral to automate incremental view maintenance, simplifying the creation of high-performance data pipelines.
Discover more about LakeChime in LinkedIn’s full blog post.

Spotlight on Slack’s female data engineers
Slack shared a blog last month highlighting the incredible work of their female data engineers across their various data teams.
By optimising data workflows with Apache Airflow and Apache Pinot, ensuring sub-second query latency. Senior Software Engineer, Jessica’s team is migrating from virtual machines to Kubernetes, using custom Python tools and automated deployments to boost efficiency.
Senior Software Engineer, Ramya talks about leading the migration from Spark 2 to Spark 3 on AWS EMR6, explaining how it enhances performance and reduces reliance on legacy systems.
Shrushti, another Senior Software Engineer transitioned Slack’s data ingestion from Secor to Bedrock and is now moving to Kafka Connect for real-time streaming. A shift that aligns with industry standards and improves system adaptability.
It’s a really interesting read and shines a light on Slack’s dedication to diversity and inclusion, as well as some of the incredible ways they’re using data. Read the full blog post to meet more inspiring engineers and discover the innovative projects shaping the future at Slack.
In conclusion…
As data continues to grow in volume and complexity, the strategies and technologies we employ must evolve. How will these innovations from Synq, Uber, LinkedIn, and Slack shape your business?
To stay ahead, organisations must keep pace with technological advancements with a culture of continuous learning and adaptation.